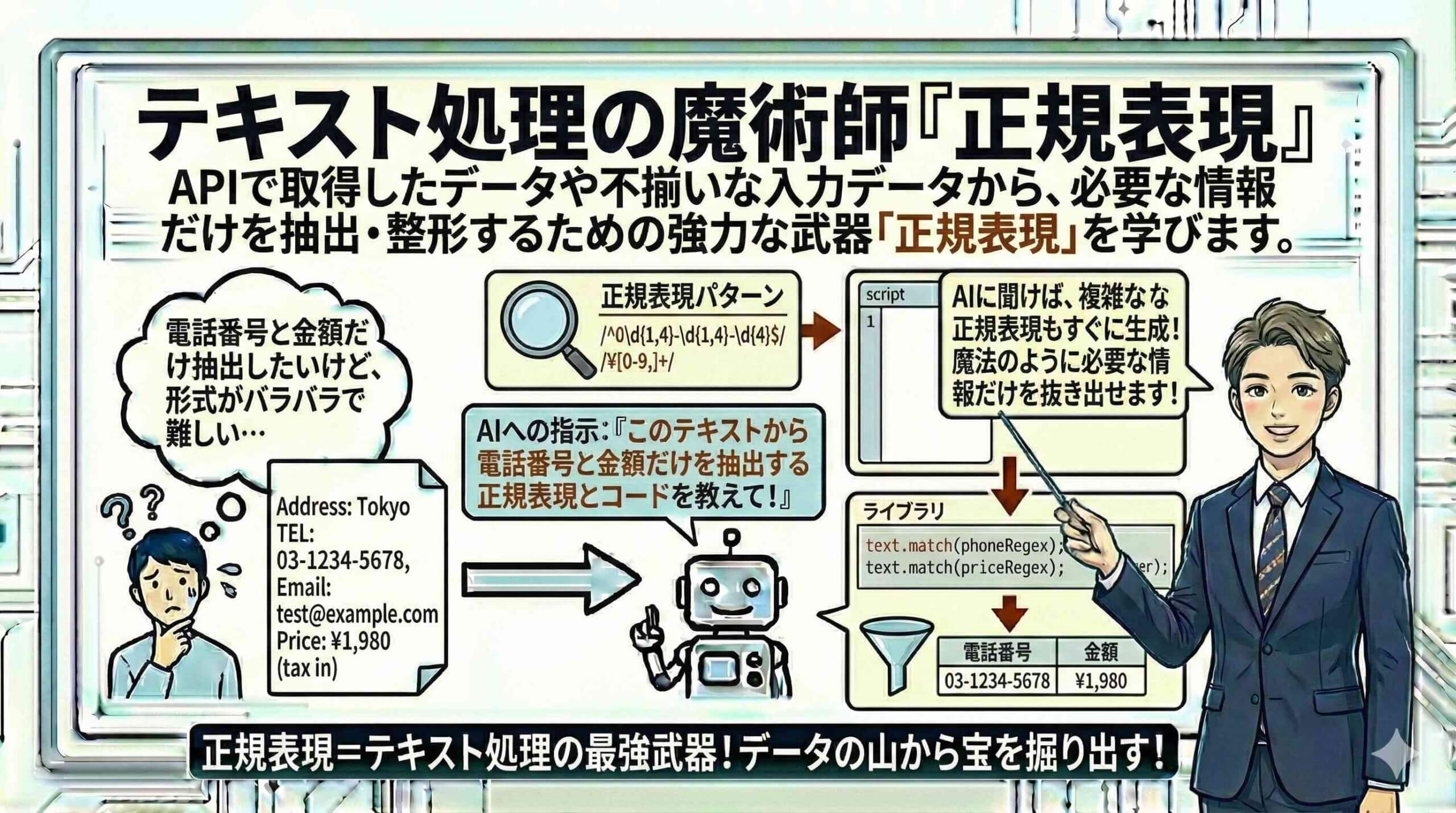
API連携で取得した生のデータと格闘する開発者の必須スキル
前章では、UrlFetchAppを使用して外部のWeb APIからデータを取得する方法を学びました。しかし、APIから返されるデータや、Webスクレイピングで取得したHTMLデータは、必ずしもそのままスプレッドシートに書き込めるような綺麗な形をしているわけではありません。不要なタグが含まれていたり、特定の部分だけを抜き出す必要があったり、あるいは表記ゆれを含んでいたりと、いわゆる「汚いデータ」であることが多々あります。このような非構造化データや複雑な文字列の中から、特定のパターンに基づいて必要な情報だけを抽出したり、整形したりするための技術が「正規表現(Regular Expression)」です。
正規表現は、GAS(JavaScript)に限らず、PythonやJavaなど多くのプログラミング言語で共通して利用される、文字列処理における世界共通語のような存在です。これを習得することは、単にGASのスキルが向上するだけでなく、エンジニアとしての基礎体力を底上げすることに直結します。例えば、「メールアドレスの形式が正しいかチェックする」「文章の中から電話番号だけをすべて抜き出す」「HTMLタグをすべて削除して本文だけを残す」といった処理を、if文やfor文で一文字ずつ判定して実装しようとすると、数百行のコードが必要になり、バグの温床となります。しかし、正規表現を使えば、わずか数行の記述で、かつ高速にこれらの処理を実現できます。本章では、一見すると暗号のように見えるこの強力な武器を、基礎から実践的なテクニックまで体系的に解説し、文字列を自由自在に操る「テキスト処理の魔術師」への道を切り開きます。
メタ文字の基礎1:位置指定と任意の文字マッチング
正規表現を構成するのは、通常の文字(aや1など)と、「メタ文字」と呼ばれる特殊な意味を持つ記号です。まずは、最も基本的なメタ文字である .(ドット)、^(ハット)、$(ドル)について理解を深めましょう。これらは、文字列の「中身」や「場所」を抽象的に表現するために使用されます。
まず .(ドット)は、「改行を除く任意の1文字」を表します。例えば、正規表現で a.c と記述した場合、これは「abc」にも「aRc」にも「a-c」にもマッチします。データの形式が一部不明確な場合や、間の文字が変動する場合に、ワイルドカードとして機能します。次に ^(ハット)は、「行の先頭」を意味します。^https というパターンは、行の始まりが「https」である場合にのみマッチします。文章の途中に出てくる「https」には反応しません。これは、URLのリストから特定のプロトコルで始まるものだけを厳密に抽出したい場合などに有効です。逆に $(ドル)は、「行の末尾」を意味します。jpg$ というパターンは、行の最後が「jpg」で終わっている文字列、つまり画像ファイル名などを特定するのに役立ちます。
開発者として重要なのは、これらを組み合わせる思考です。例えば ^A.Z$ というパターンは、「Aで始まり、間に何らかの1文字があり、Zで終わる、合計3文字の行」という非常に厳密な条件を定義しています。このように、正規表現は文字そのものではなく「構造」や「位置」を定義することで、曖昧なデータの中から意図したデータを正確に捉えることを可能にします
メタ文字の基礎2:量指定子による繰り返しの制御
文字列パターンにおいて、「ある文字が何回繰り返されるか」を指定することは非常に重要です。これを制御するのが「量指定子」と呼ばれるメタ文字群、*(アスタリスク)、+(プラス)、?(クエスチョン)です。これらは直前の文字が何回出現するかを定義します。
* は「0回以上の繰り返し」を意味します。go*d は、「god」「good」「gooood」だけでなく、oが存在しない「gd」にもマッチします。初心者が陥りやすいのは、この「0回も含む」という点です。あるはずの文字がなくてもマッチしてしまうため、使用には注意が必要です。一方、+ は「1回以上の繰り返し」を意味します。go+d は「god」や「good」にはマッチしますが、「gd」にはマッチしません。必ずその文字が存在してほしい場合は、* ではなく + を選択すべきです。そして ? は「0回または1回」を意味します。これは「あってもなくても良い(オプショナルな)文字」を表現する際に使われます。例えば https? というパターンは、「http」と「https」の両方にマッチします。sがあってもなくても許容されるからです。
これらの量指定子を、前述の . と組み合わせることで、表現力は飛躍的に向上します。よく使われる .* という組み合わせは、「何らかの文字が0回以上続く=あらゆる文字列」を意味します。APIから取得したデータの中で、タグとタグの間に挟まれた任意の長さの文字列を取得したい場合などに頻出するパターンです。ただし、この強力なパターンは諸刃の剣でもあり、後述する「貪欲マッチ」の問題を引き起こす原因ともなります。
文字クラスと範囲指定:特定の種類の文字を狙い撃つ
^ や $ で位置を特定し、* や + で量を指定できるようになりましたが、より具体的に「数字だけ」や「アルファベットだけ」を指定したい場面は頻繁にあります。これを実現するのが [](ブラケット)を用いた「文字クラス」です。
[abc] と記述すると、「aまたはbまたはcのいずれか1文字」という意味になります。これだけでは限定的ですが、ハイフンを使った範囲指定 [a-z] とすることで、「aからzまでの小文字アルファベットのいずれか1文字」を表現できます。同様に は「数字1文字」、[A-Z] は「大文字アルファベット1文字」を表します。これらを組み合わせて [a-zA-Z0-9] とすれば、「英数字のいずれか」を指定できます。
さらに、[] の中で ^ を使うと「否定」の意味に反転します(行頭の意味ではなくなります)。[^0-9] は「数字以外の1文字」という意味になります。これは、データクレンジングにおいて「数値データの中に紛れ込んだ不要な記号や文字を除外したい」といったケースで威力を発揮します。また、GAS(JavaScript)には、よく使う文字クラスのショートカットも用意されています。\d は と同じ意味(数字)、\w は [a-zA-Z0-9_] と同じ意味(英数字とアンダースコア)、\s は空白文字(スペース、タブ、改行)を表します。APIから取得したJSONデータ内の日付フォーマット 2023-01-01 をチェックする際、\d{4}-\d{2}-\d{2}(数字4桁-数字2桁-数字2桁)のように記述することで、厳密なフォーマット検証が可能になります。
グループ化とキャプチャ:情報の抽出と再利用
正規表現の真骨頂は、単にマッチするかどうかを判定するだけでなく、マッチした部分の一部を「抽出(キャプチャ)」して利用できる点にあります。これを実現するのが ()(丸括弧)による「グループ化」です。
例えば、<h1>Title</h1> というHTMLタグのような文字列から、中身の「Title」だけを取り出したいとします。この場合、<h1>(.*)</h1> というパターンを作成します。.* の部分を () で囲むことで、プログラムはその部分にマッチした文字列を一時的にメモリに保存します。GASの match() メソッドを使用すると、マッチした全体の結果に加えて、この () で囲まれた部分の内容が配列として返されます。これにより、タグを取り除いた中身だけのデータを簡単に取得できます。
この機能は、API連携において非常に重要です。例えば、APIから返ってきたレスポンスの中に ID: 12345, Name: User という文字列があり、ID番号だけを抜き出したい場合、ID: (\d+) という正規表現を使います。これにより、”ID: ” に続く数字の列をキャプチャし、変数としてプログラム内で利用できるようになります。また、() は (abc)+ のように、複数の文字をひとまとまりとして繰り返しを適用したい場合にも使用されます。開発者として、単なる検索だけでなく、この「抽出」の概念を理解することで、非構造化データを構造化データへと変換するスキルが身につきます。
貪欲マッチと非貪欲マッチ:初心者が陥る最大の罠
正規表現を使ってHTMLやタグ付きのテキストを処理する際、多くの開発者が一度は直面するトラブルが「貪欲マッチ(Greedy Match)」です。これは、量指定子 * や + が、デフォルトでは「条件を満たす限り、できるだけ長く」文字列にマッチしようとする性質を指します。
具体例で考えましょう。<div>A</div><div>B</div> という文字列に対して、<div>.*</div> という正規表現を適用した場合、どのような結果になるでしょうか。期待するのは <div>A</div> という最初のタグの塊ですが、実際には文字列全体の <div>A</div><div>B</div> にマッチしてしまいます。なぜなら、最後の </div> までを含めた方が、マッチする範囲が長くなるからです。これが「貪欲」と呼ばれる所以です。
これを防ぎ、最初に見つかった </div> でマッチを止めさせるには、「非貪欲マッチ(Non-Greedy Match)」を使用します。記述方法は簡単で、量指定子の後ろに ? を付けます。つまり <div>.*?</div> と記述します。この ? は、「できるだけ短くマッチする」という指示になります。この非貪欲マッチを使うことで、<div>A</div> と <div>B</div> をそれぞれ別の要素として正しく認識できるようになります。スクレイピングやログ解析など、特定の区切り文字で挟まれたデータを抽出する場面では、この *? や +? の使い分けが、意図通りのデータを取得できるかどうかの分かれ目となります。
matchメソッドの実践:データ抽出のコーディング
それでは、GASのコード上で正規表現を使ってデータを抽出する方法を見ていきましょう。文字列オブジェクトに対して match() メソッドを使用します。引数には、/パターン/ の形式で正規表現リテラルを渡すか、new RegExp("パターン") で作成したオブジェクトを渡します。
例えば、ある文字列 text からURLを抽出したい場合、以下のように記述します。
const text = '詳細は https://example.com をご覧ください';
const pattern = /https?:\/\/[\w/:%#\$&\?\(\)~\.=\+\-]+/;
const result = text.match(pattern);
match() メソッドの戻り値は、マッチしなかった場合は null、マッチした場合は配列となります。この配列の0番目の要素には「マッチした文字列全体」が、1番目以降の要素には () でキャプチャしたグループの内容が入ります。
開発者として注意すべきは、null のハンドリングです。マッチしなかった場合に result にアクセスしようとするとエラーが発生し、スクリプトが停止してしまいます。必ず if (result) { ... } のように、マッチしたかどうかの判定を入れてからデータを利用するような防御的プログラミングを心がける必要があります。また、全文検索を行って複数のマッチ結果すべてを取得したい場合は、正規表現の末尾に g フラグ(Global)を付けて /パターン/g とし、match() メソッドを実行します(ただし、match() で g フラグを使った場合、キャプチャグループの取得挙動が変わる点には注意が必要です。より高度な抽出には exec() メソッドのループ処理が用いられることもあります)。
replaceメソッドの実践:データの整形と置換
正規表現のもう一つの主要な用途は、文字列の「置換」です。GASの replace() メソッドは、第一引数に正規表現、第二引数に置換後の文字列を指定することで、パターンに合致した部分を書き換えることができます。
例えば、電話番号のハイフンをすべて取り除きたい場合、以下のように記述します。
const phoneNumber = '090-1234-5678';
const formattedNumber = phoneNumber.replace(/-/g, '');
ここで重要なのが g フラグです。これを付けないと、最初に見つかったハイフンしか置換されず、0901234-5678 となってしまいます。g フラグを付けることで、対象の文字列内にあるすべてのパターンを置換できます。
また、replace() メソッドはキャプチャグループとの組み合わせでさらに強力になります。置換後の文字列の中で $1, $2 といった特殊な変数を使うことで、検索時に () でキャプチャした内容を、置換後の文字列に埋め込むことができます。例えば、2023/01/01 という日付を 2023年01月01日 に変換したい場合、/(\d{4})\/(\d{2})\/(\d{2})/ というパターンで検索し、$1年$2月$3日 という文字列に置換することで、元の数字を維持したままフォーマットだけを変更することが可能です。これは、CSVデータの整形や、表記ゆれの統一など、データクレンジング業務において極めて実用的なテクニックです。
実務シナリオ:APIレスポンスからの不要タグ除去
実際の業務自動化における正規表現の活用シーンとして、「APIから取得したテキストに含まれるHTMLタグを除去する」というケースを考えてみましょう。CMSやメール配信システムなどのAPIでは、本文データがHTML形式で返ってくることがよくあります。これをそのままスプレッドシートに書き込むと、タグがそのまま表示されてしまい、非常に見づらくなります。
この場合、以下のような関数を作成して処理します。
function removeTags(htmlText) {
return htmlText.replace(/<.*?>/g, '');
}
ここでは、先ほど学んだ非貪欲マッチ .*? を使用しています。これにより、< で始まり > で終わる最短の文字列、つまりすべてのHTMLタグを空文字に置換(削除)することができます。もしここで貪欲マッチ .* を使ってしまうと、行頭の開始タグから行末の終了タグまでがすべて削除され、本文まで消えてしまう可能性があります。
さらに、実務では「実体参照」の処理も必要になることがあります。例えば & や < といった文字コードです。これらも正規表現を使って replace(/&/g, '&') のように通常の文字に戻す処理を加えることで、人間が読みやすい綺麗なテキストデータへと加工することができます。API連携と正規表現によるデータ加工はセットで考えるべきスキルです。
RegExpオブジェクトと動的なパターン生成
これまでは /パターン/ という形で、コード内に正規表現を固定で記述する方法(正規表現リテラル)を解説しましたが、開発の現場では「検索したいパターンが動的に変わる」という状況もあります。例えば、スプレッドシートのセルに入力されたキーワードを使って、文章内を検索したい場合などです。
このような場合に利用するのが RegExp オブジェクトです。
const keyword = sheet.getRange('A1').getValue(); // セルからキーワード取得
const pattern = new RegExp(keyword, 'g');
const result = text.match(pattern);
このように new RegExp() コンストラクタを使用することで、変数の中身を正規表現のパターンとして扱うことができます。ただし、この方法を使う場合、バックスラッシュ \ の扱いに注意が必要です。文字列の中でバックスラッシュを表現するには \\ と重ねて記述する必要があるため、\d(数字)を使いたい場合は new RegExp("\\d") と書かなければなりません。
AIに正規表現の生成を依頼する際も、「GASの new RegExp で使える形式で書いて」と指示することで、エスケープ処理が適切に施されたコードを得やすくなります。動的なパターンの生成は、検索ツールやフィルタリング機能を自作する際に必須となるテクニックです。
開発者としての品質:正規表現の可読性と保守性
正規表現は非常に強力ですが、複雑になればなるほど「書いた本人しか読めない」という状態になりがちです。^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$ のようなパスワード検証の正規表現は、パッと見ただけでは何をしているのか理解するのが困難です。
プロフェッショナルな開発者としては、複雑な正規表現を使用する際には必ずコメントを添え、そのパターンが何を意図しているのかを説明する責任があります。また、あまりに長大で複雑な正規表現を一行で書こうとするのではなく、処理をいくつかに分割したり、変数名に意味を持たせたりして、可読性を維持する工夫も大切です。
例えば、const emailPattern = /.../ のように、パターン自体を変数に格納し、その変数名で用途を明示するだけでも、コードの読みやすさは劇的に向上します。AIを活用する場合も、「この正規表現の意味を解説するコメントもコードに追加して」と指示することで、ブラックボックス化を防ぐことができます。正規表現は「魔法」ですが、その魔法を制御し、チーム全員が理解できる形に落とし込むことが、開発者の腕の見せ所です。次章では、整理されたデータを保存・管理するための「Googleドライブとの連携」について学んでいきます。