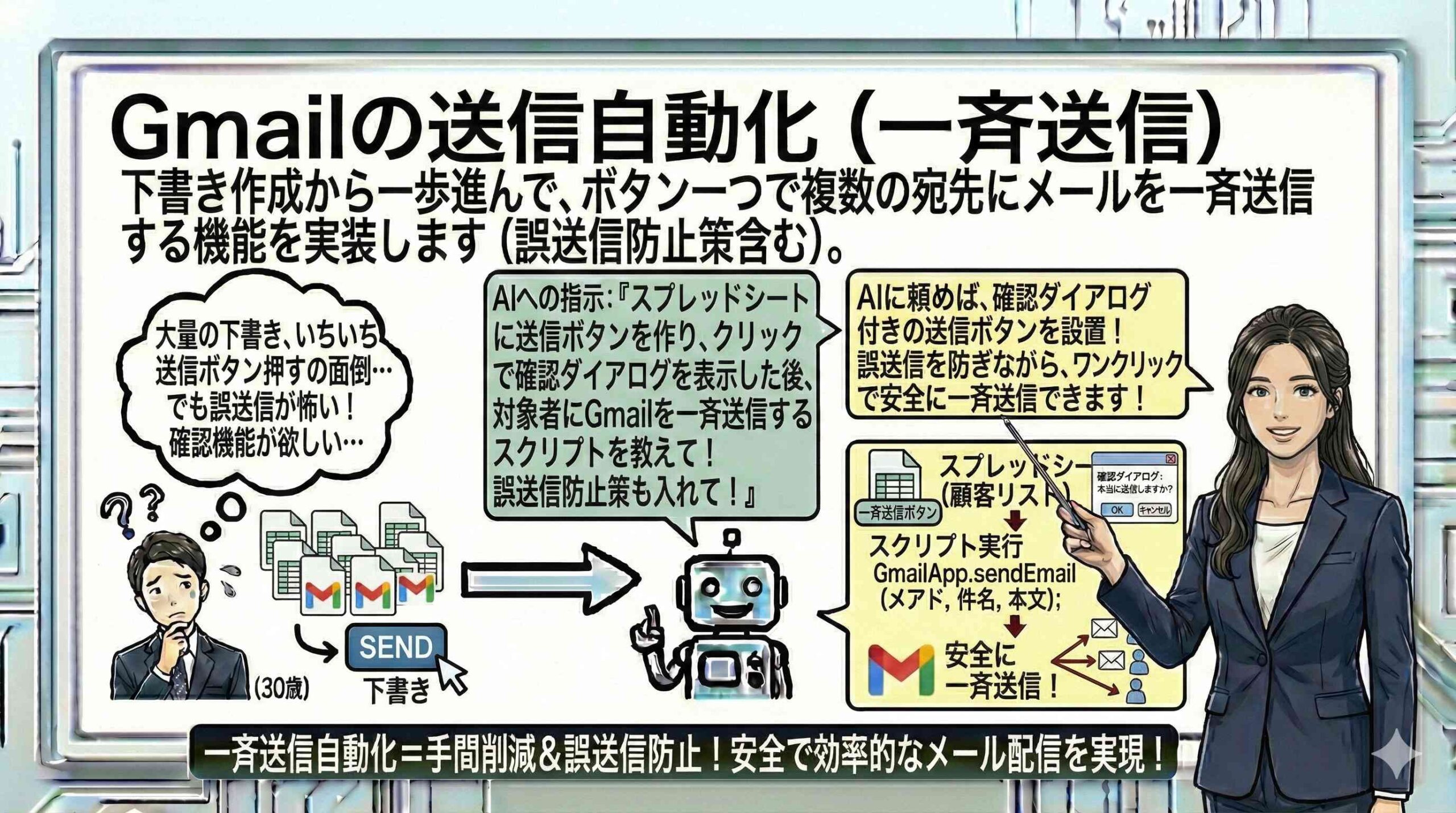
受信トレイのデータベース化による非構造化データの資産化
ビジネスの現場において、メールボックスは情報の宝庫であると同時に、カオスの温床でもあります。日々絶え間なく届くメールの中には、顧客からの注文書、システムからの障害アラート、問い合わせフォームからの通知など、企業の意思決定や業務遂行に直結する重要なデータが大量に含まれています。しかし、これらがメールボックスの中に留まっている限り、それらは単なる「テキストの塊(非構造化データ)」に過ぎません。集計も分析もできず、他のシステムと連携することも困難です。多くの現場では、担当者がメールを目視で確認し、必要な情報をExcelや基幹システムに手作業で転記するという業務が行われています。このプロセスは、生産性を著しく低下させるだけでなく、転記ミスや見落としといったヒューマンエラーのリスクを常に孕んでいます。
Google Apps Script(GAS)を活用し、Gmailを「情報の入り口(インプット)」、スプレッドシートを「データベース(格納庫)」と定義して連携させることで、この課題を根本から解決できます。メール本文に含まれる重要情報を自動的に抽出し、構造化データへと変換するパイプラインを構築するのです。これにより、例えば注文メールが届いた瞬間にスプレッドシートの売上台帳が更新されたり、サーバーからの障害通知を検知してインシデント管理表に起票したりといった、高度な自動化が可能になります。
これは単なる作業の自動化を超え、埋もれていたデータを資産として活用可能な状態にする「DX(デジタルトランスフォーメーション)」の第一歩と言えます。本章では、GmailAppクラスを駆使した検索・抽出のエンジニアリングから、正規表現を用いた高度なテキスト解析、そしてシステムを安定稼働させるための重複排除ロジックまで、実務に即したメール収集システムの構築手法を詳細に解説します。
GmailApp.searchメソッドによる検索クエリの最適化とフィルタリング
メール収集システムのパフォーマンスと精度を左右する最初の、そして最も重要なステップは、処理対象となるメールを正確に特定することです。無関係なメールまでスクリプトで処理しようとすれば、実行時間の浪費や誤ったデータの取り込みにつながります。これを行うために使用するのが GmailApp.search(query, start, max) メソッドです。このメソッドは、GmailのWeb画面上部にある検索ボックスで使用する検索演算子(クエリ)を、そのままコード内で利用できるという非常に強力な機能を持っています。
例えば、「件名に『注文書』を含み、かつ未読のメール」を取得したい場合、単に文字列検索をするのではなく、 "subject:注文書 is:unread" というクエリを指定します。さらに、 "after:2025/01/01" や "newer_than:1d" といった期間指定の演算子を組み合わせることが重要です。過去数年分のメールを毎回検索対象に含めていては、処理速度が劇的に低下し、APIの実行制限に抵触する恐れがあります。直近24時間や特定の日付以降のメールに対象を絞り込むことで、システムのリソースを節約し、高速な処理を実現できます。
また、 search メソッドの第2引数(開始位置)と第3引数(最大取得件数)を適切に設定することも、プロフェッショナルな設計には不可欠です。例えば "0, 50" と指定することで、検索結果の最初の50件のみを取得するように制限できます。GASには1回のスクリプト実行時間が最大6分という「6分の壁」が存在します。大量のメールがヒットした場合でも、一度に処理する件数を制限することでタイムアウトエラーを未然に防ぎ、次回の実行で残りを処理するといった堅牢な設計が可能になります。適切なクエリ設計こそが、APIリソースの節約と処理速度の向上、そしてシステムの安定性に直結する重要な要素なのです。
スレッドとメッセージの階層構造の理解とループ処理
Gmailからデータを抽出する際、多くの初学者がつまずくポイントが「スレッド」と「メッセージ」の階層構造です。Gmailのデータ構造は一見フラットに見えますが、実際には「スレッド(会話のまとまり)」の中に複数の「メッセージ(個々のメール)」が含まれるという親子関係を持っています。 GmailApp.search メソッドが返すのは GmailMessage オブジェクトではなく、 GmailThread オブジェクトの配列です。個々のメール本文にアクセスするためには、取得したスレッドオブジェクトに対してさらに getMessages() メソッドを実行し、 GmailMessage オブジェクトの配列を取得するという2段階の手順が必要です。
したがって、スクリプトの構造としては、まず取得したスレッド群に対してループ処理を行い、そのループの中でさらにメッセージ群に対してループ処理を行う「二重ループ」の記述が基本となります。しかし、業務要件によっては、必ずしもすべてのメッセージを処理する必要はありません。例えば、問い合わせ対応の履歴を全て取得したい場合は全メッセージを走査する必要がありますが、最新の注文状況だけを知りたい場合は、スレッド内の「最新のメッセージ」だけを処理すれば十分です。その際は、スレッド内の全メッセージを回すのではなく、配列の最後尾(最新)のメッセージのみを対象とするロジックを組むことで、処理効率を大幅に向上させることができます。
開発者は、対象となる業務フローが「会話の履歴すべてを追う必要があるのか」、それとも「最新の状態のみが必要なのか」を見極め、適切なループ構造を選択する必要があります。また、スレッドの概念を無視して実装すると、返信メールや転送メールが混在した際に予期せぬデータを拾ってしまったり、逆に必要なデータを見落としたりする原因となります。この階層構造を正しく理解し、意図通りにオブジェクトを操作できる能力が、正確なデータ収集システムを構築するための鍵となります。
メッセージ情報の抽出とオブジェクト操作
GmailMessage オブジェクトを取得できれば、そこからメールに関する様々なメタデータを抽出することが可能です。 getDate() で受信日時、 getFrom() で送信者、 getSubject() で件名といった基本情報を取得し、これらをスプレッドシートの各列に対応させて格納することで、後からフィルタリングやソートが可能な管理台帳として機能します。
特に注意が必要なのが送信者情報(From)の扱いです。 getFrom() メソッドで取得できる文字列は、通常 "山田 太郎 <taro@example.com>" のように、表示名とメールアドレスが混在した形式になっています。データベースとして活用する場合、表示名とメールアドレスは別々のカラムに分けて管理したいケースが多いため、正規表現や文字列操作を用いてパース(解析・分割)する処理が必要となります。また、 getTo() や getCc() を用いて宛先情報を取得し、特定のメーリングリスト宛のメールだけを抽出したり、 getAttachments() を用いて添付ファイルを取得しGoogleドライブへ保存したりといった応用も可能です。
これらの取得したデータは、そのままスプレッドシートに書き込むのではなく、データの意味(セマンティクス)を考慮した型変換を行うことが推奨されます。例えば、日時は Utilities.formatDate を用いて指定のフォーマット(yyyy/MM/dd HH:mm:ss)に変換し、数値が含まれる場合は文字列から数値型へ変換しておくことで、後のデータ分析フェーズでの利便性が高まります。単にテキストとして保存するのではなく、後続のプロセスでデータがどのように利用されるかを想像し、最適な形式に整えてから保存することが、プロフェッショナルな実装の基本です。
getPlainBodyと正規表現による高度なテキスト解析
抽出したデータをスプレッドシートに書き込む際、初心者が見落としがちなのがAPI呼び出しのコストです。ループ処理の中で1行ずつ メール収集システムの核心部分である、メール本文からのデータ抽出について解説します。近年、HTMLメールが一般的になっていますが、データ抽出の観点からはHTMLタグはノイズとなります。 getBody() メソッドではHTMLタグが含まれたソースコードが返ってくるため、解析が困難です。そこで、 getPlainBody() メソッドを使用してプレーンテキスト(純粋なテキストデータ)を取得します。
取得したテキストから「注文ID」や「請求金額」、「担当者名」といった特定の値を抜き出すためには、「正規表現(Regular Expression)」の活用が不可欠です。正規表現とは、文字列のパターンを表現するための記述方法です。例えば、本文中に「合計金額:10,000円」という記述がある場合、JavaScriptの match(/合計金額:([\d,]+)円/) といったパターンマッチングを用いることで、数値部分のみをピンポイントで抽出できます。
正規表現は非常に強力なツールですが、同時に「諸刃の剣」でもあります。メールのフォーマットが送信元によって微妙に異なっていたり、改行位置が変わっていたりするだけで抽出に失敗する脆さを持っています。そのため、開発者は様々なパターンのメールを想定して正規表現を設計する必要があります。また、万が一抽出に失敗した場合でもシステム全体が停止しないよう、 try...catch 構文による例外処理を組み込むことが重要です。抽出できなかった項目には「抽出エラー」や「要確認」といったフラグを立ててスプレッドシートに記録し、人間が後からフォローできるようなフェイルセーフな設計を行うことが求められます。
スプレッドシートへの高速書き込みとバッチ処理の実装
抽出したデータをスプレッドシートに書き込む際、GAS初心者が見落としがちなのが「API呼び出しのコスト」です。ループ処理の中で1通メールを処理するたびに appendRow() メソッドや setValue() メソッドを呼び出して書き込む方法は、コードが単純で分かりやすい反面、Googleのサーバーとの通信回数が膨大になり、処理速度が劇的に低下します。数件のメールなら問題ありませんが、数百件を処理する場合、これは致命的なボトルネックとなり、実行時間制限(6分)を超える原因となります。
この問題を解決するために、抽出したデータを一度スクリプト内の配列(二次元配列)にすべて格納し、処理の最後に getRange().setValues(配列) メソッドを使用して、一度のAPI呼び出しでまとめて書き込む「バッチ処理」を実装します。これにより、実行時間を数分の一から数十分の一に短縮することが可能です。また、データ量が多い場合は、既存データの最終行を getLastRow() で取得し、その直下の範囲を正確に指定して書き込むことで、データの整合性を保ちながら高速な追記を実現します。
さらに、大量のデータを扱う場合は、スプレッドシートのセル数制限(最大1000万セル)にも注意を払う必要があります。古いデータを定期的にアーカイブするか、BigQueryなどのデータベースへ移行するライフサイクル管理も視野に入れた設計が、長期的な安定運用には不可欠です。パフォーマンスを意識したコーディングは、単に速いだけでなく、システムリソースを大切に扱うプロフェッショナルの作法と言えます。
一意のID管理による重複取り込みの完全防止
定期的にスクリプトを自動実行させてメールを収集するシステムにおいて、最大の技術的課題は「同じメールを何度も重複して取り込んでしまうこと」です。検索クエリで is:unread (未読)を指定し、処理後に markRead() で既読にする運用も一つの解ですが、既読・未読ステータスはユーザーの操作によって容易に変わってしまうため、システム的な信頼性は低くなります。ユーザーが誤って未読に戻してしまった場合、データが重複して登録されてしまいます。
確実な重複防止策として、各メールが持つ世界で唯一の識別子である「メッセージID( message.getId() )」を利用します。スプレッドシートに「メッセージID管理列」を設け、新規書き込み時にそのIDも記録しておきます。次回の実行時には、まずスプレッドシート上のID一覧を取得して配列に格納し、処理しようとしているメールのIDがその配列内に存在するかを Array.includes() や indexOf() 、あるいは Set オブジェクトを使ってチェックします。
IDが存在する場合はスキップし、存在しない場合のみ新規データとして取り込むというロジックを実装することで、何度スクリプトを実行してもデータが重複しない「冪等性(Idempotency)」を担保したシステムを構築できます。このID管理手法は、メール連携だけでなく、カレンダー連携や外部API連携など、あらゆる同期処理において基本となる重要な設計思想です。
時限式トリガーによる自動実行サイクルの確立とクォータ管理
スクリプトが完成したら、人間が実行ボタンを押さなくてもバックグラウンドで動作するように「トリガー」を設定します。GASのエディタ画面から「トリガー」を選択し、「時間主導型」のイベントとして設定します。例えば「1時間おき」に設定すれば、システムは24時間365日、新しい注文メールがないかを監視し続けます。実行間隔は、業務のリアルタイム性への要求と、GASの実行回数制限(Quotas)のバランスを考慮して決定します。
あまりに頻繁(例:1分ごと)に実行すると、1日あたりのトリガー実行総時間の制限(Google Workspaceアカウントで6時間/日、無料アカウントで90分/日)に達する可能性があります。一般的な業務であれば、1時間ごとや数時間ごとの実行で十分なケースが多いですが、即時性が求められる場合はメール受信をトリガーとする工夫が必要になる場合もあります。また、エラー発生時の通知設定も忘れずに行いましょう。
さらに、万が一処理が長時間化して6分の壁に近づいた場合、スクリプトの開始時間を記録しておき、経過時間が5分を超えたら処理を中断・保存して終了するロジックを組み込むことも推奨されます。残りのメールは次回のトリガー実行時に処理されるように設計することで、大量のデータがあってもシステムが破綻することなく、確実に全件を処理できる堅牢なアーキテクチャとなります。
セキュリティとプライバシー情報の取り扱い:開発者の倫理と責任
メールには、顧客の氏名、住所、電話番号、クレジットカード情報の一部といった個人情報や、企業の機密情報が含まれることが多々あります。これらの情報を扱うシステムを開発する際、セキュリティとプライバシーの保護は機能要件以上に優先されるべき事項です。スクリプト内で取得したデータをデバッグのために console.log で出力する際は、個人情報がそのままログに残らないように注意する必要があります。Google Cloud Platformのログエクスプローラなどに個人情報が出力されると、ログの閲覧権限を持つ他の開発者にも情報が見えてしまう可能性があります。
また、スプレッドシート自体の閲覧権限を適切に管理し、関係者以外がデータにアクセスできないようにすることも、開発者ではなく管理者としての重要な責務です。GASの「スクリプトプロパティ」を活用して、検索キーワードや特定のメールアドレスなどの設定値をコードから分離し、コード自体を見ても機密性が守られるような工夫も必要です。さらに、OAuthスコープの確認を行い、スクリプトが必要とする権限(Gmailの読み取り、スプレッドシートへの書き込みなど)が最小限になるように管理することも、セキュリティリスクを低減させるための重要なプラクティスです。
継続的なメンテナンスと公式リファレンスの活用
メールのフォーマット変更や業務ルールの変更に伴い、スクリプトの修正が必要になることは避けられません。長期的に安定して稼働するシステムを維持するためには、作成したコードが「読みやすく」「変更しやすい」状態であることが求められます。変数名や関数名を分かりやすく付ける、複雑なロジックにはコメントを残す、といった基本的なコーディング規約を遵守しましょう。
また、Googleのサービスは頻繁にアップデートされます。GmailAppクラスのメソッドに追加機能があったり、仕様変更があったりする情報をキャッチアップするために、公式ドキュメント(Reference)を定期的に参照する習慣をつけることが重要です。Google Cloud Skills Boostなどの学習リソースを活用し、GASだけでなくGoogle Cloud全体の知識を深めることで、例えば「データ量が増えたからBigQueryに移行しよう」といった、より高度なアーキテクチャへの移行判断も可能になります。
AI時代の開発者としては、AIにコードを書かせるだけでなく、AIが生成したコードが最新の公式リファレンスに準拠しているか、セキュリティ上の問題がないかを検証し、責任を持ってデプロイする姿勢が求められます。自身が得た知見をブログや勉強会で共有することで、フィードバックを得られ、より深い理解へと繋がります。技術力と倫理観を兼ね備えたプロフェッショナルとして、自動化システムを構築・運用していきましょう。