定量データの言語化による意思決定プロセスの高速化
ビジネスの現場において、売上データやKPI(重要業績評価指標)の集計は自動化が進んでいますが、その数字が何を意味するのかを解釈し、次のアクションを導き出す「定性的な分析」のプロセスは、依然として人間の手作業に依存しています。担当者がスプレッドシートの行列を眺め、変化の要因を探り、レポートとして文章化する作業は、高度な知的生産活動である一方で、多大な時間を要するボトルネックでもあります。Google Apps Script(GAS)と生成AIのAPIを統合することで、この「データの解釈」と「言語化」のプロセスをシステム化することが可能になります。これは単なる省力化ではなく、データが更新された瞬間にインサイト(洞察)が提示される「リアルタイム経営判断支援システム」への昇華を意味します。
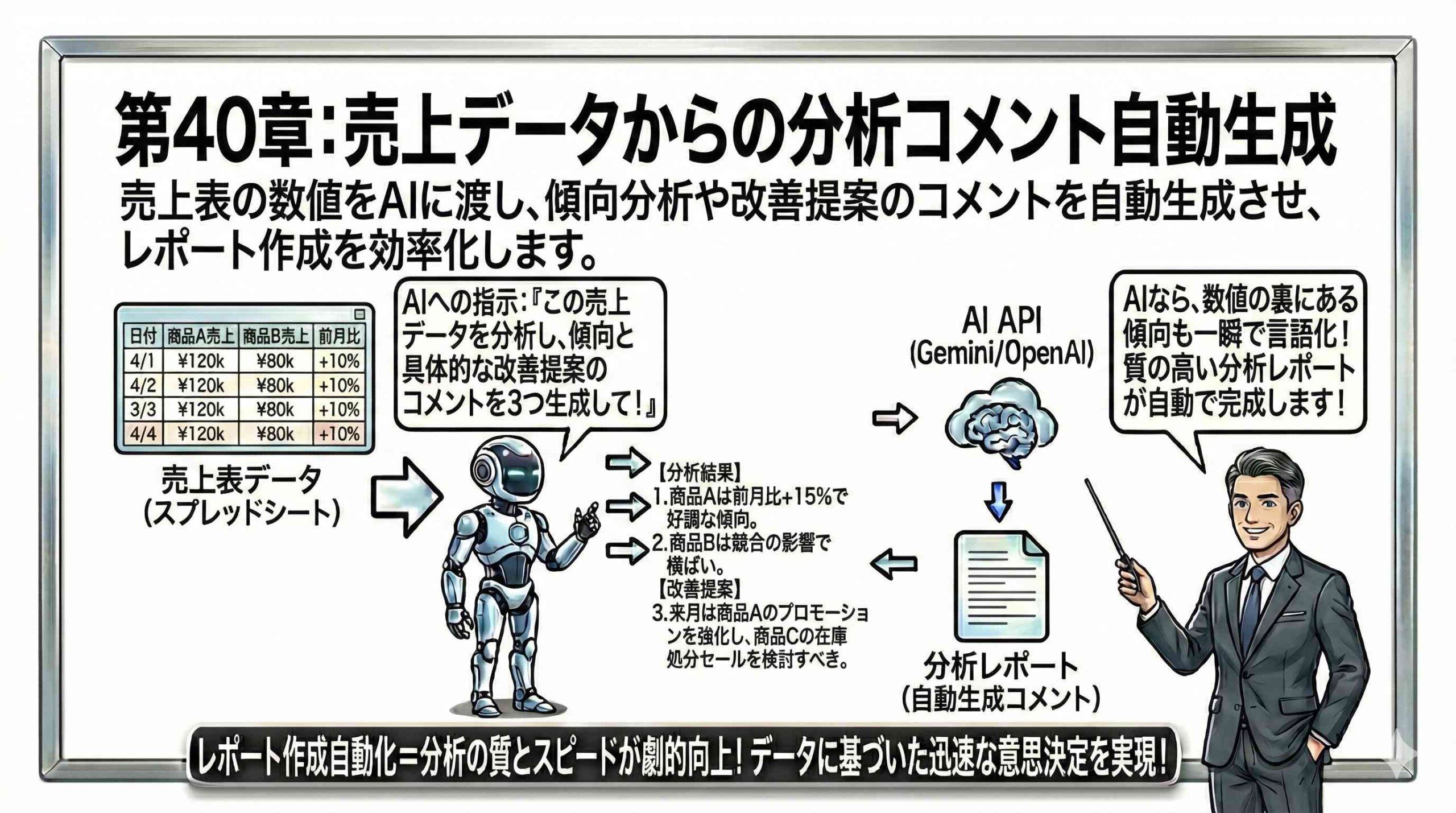
本章では、スプレッドシート上の売上データを構造化してAIに渡し、傾向分析、異常値の検出、そして具体的な改善提案を含むコメントを自動生成するアプリケーションを構築します。開発者には、単に数値を文字列として渡すだけでなく、AIが正しく文脈を理解できるようなデータプレパレーション(前処理)の設計と、AI特有の「計算ミス(ハルシネーション)」を防ぐためのアーキテクチャ設計が求められます。
定量的な事実と定性的な解釈をプログラム上で融合させ、経営層や現場マネージャーが即座に意思決定できる状態を作り出すための、実践的なエンジニアリング手法を深掘りします。
データプレパレーションとコンテキストのシリアライズ
AIに的確な分析を行わせるための第一歩は、スプレッドシート上の2次元データを、AIが解釈可能な形式に変換する「シリアライズ」の工程です。人間は表形式の視覚情報から直感的に「売上が落ちている」と判断できますが、AI(LLM)にとっては、それは単なるトークンの羅列に過ぎません。したがって、getDataRange().getValues() で取得した配列データを、意味のあるJSONオブジェクトやマークダウン形式のテキストに変換する必要があります。例えば、単に という数値を渡すのではなく、{"月": "4月", "売上": 100, "前年比": "105%"} のように、各数値が何を表しているのかというメタデータを付与して構造化します。
また、単月のデータだけでなく、過去数ヶ月分のトレンドや、昨対比、予算比といった比較対象となるデータをコンテキストとして含めることが重要です。プロフェッショナルな実装では、シート上の生データだけでなく、ビジネスの背景情報(例:「今月は大型キャンペーンを実施した」「季節性の変動要因がある」など)をシステムプロンプトとして注入する設計にします。
これにより、AIは単なる数値の増減だけでなく、その背景にある因果関係を推論できるようになります。Sourceの事例でも見られるように、ドキュメントやデータの構造を整形し、AIが理解しやすい形に加工する前処理関数(formatDocumentDataなど)の実装が、分析精度を左右する重要なファクターとなります。
数値計算の分離とハルシネーションの回避戦略
生成AIを数値分析に活用する際、開発者が最も警戒すべきリスクは「計算間違い(ハルシネーション)」です。大規模言語モデルは「次に来る確率の高い単語」を予測する仕組みであり、厳密な数学的計算を行うエンジンではありません。したがって、「売上の合計を計算して」や「前月比のパーセンテージを算出して」といった指示をAIに投げることは、システム設計として誤りです。計算結果が微妙にズレていたり、全くのデタラメが出力されたりするリスクがあります。
正しいアーキテクチャは、「計算はGAS(JavaScript)またはスプレッドシート関数で行い、AIはその計算結果の意味付け(解釈)のみを行う」という役割分担です。例えば、成長率や達成率、構成比といった指標は事前にプログラム側で計算し、その確定値をプロンプトに埋め込みます。「前月比は120%でした。この要因を分析してください」という指示であれば、AIはその言語能力を最大限に発揮できます。Sourceのプロンプト例にあるように、「数値計算はできるだけ避け、報告書に記載された数値をそのまま引用してください」といった制約を明示的に加えることも有効なテクニックです。
計算ロジックと推論ロジックを明確に分離し、数値の正確性を担保するのは、AIではなく開発者の責任であることを肝に銘じてください。
分析用プロンプトの構造化とロール定義
質の高い分析コメントを引き出すためには、プロンプトエンジニアリングの技術が不可欠です。漠然と「分析して」と頼むのではなく、AIに対して具体的な「役割(ロール)」と「出力要件」を定義します。例えば、「あなたは経験豊富な経営コンサルタントです。以下の売上データを分析し、経営陣に対して報告すべき3つの重要課題と、それぞれの解決策を提案してください」といったペルソナ設定を行います。さらに、分析の視点(Viewpoint)を指定することも有効です。「製品別の売上構成比の変化に着目して」「特定の地域での異常値を検出して」といった具体的な指示を与えることで、AIの注目点をコントロールできます。
SourceやSourceで示されているように、プロンプトを「課題の詳細分析」「具体的な対策提案」「今後の戦略的方向性」といったセクションに分割し、それぞれのセクションで何を記述すべきかを詳細に指示する「構造化プロンプト」の手法を取り入れます。また、出力形式についても、「箇条書きで」「結論を先に」「専門用語を使わずに」といった制約を設けることで、そのままレポートとして利用可能なテキストを生成させることができます。プロンプトは一度書いて終わりではなく、出力結果を見ながら微調整を繰り返す(イテレーション)必要があります。
このプロセスを効率化するために、プロンプト自体をスプレッドシートの特定セルで管理し、コードを修正せずにプロンプトを調整できるような設計にしておくことも、運用性を高めるためのポイントです。
APIリクエストの最適化とトークン管理
売上データは往々にして膨大な量になります。全期間、全商品のデータをそのままAPIに投げると、トークン制限(入力文字数制限)を超過したり、API利用コストが増大したりする可能性があります。プロフェッショナルな開発では、必要なデータのみを抽出(フィルタリング)して送信する最適化処理が求められます。例えば、売上の上位20%の商品(パレートの法則)に絞って分析させる、あるいは変動幅が一定以上のデータのみを抽出して「要確認リスト」として渡すといったロジックをGAS側で実装します。
Sourceでも、入力テキストが長すぎる場合に適切な長さに切り詰める処理(truncatedText)が実装されています。このように、APIの仕様(コンテキストウィンドウサイズ)を理解し、データ量を制御するガードレールを設けることは必須です。また、UrlFetchAppを用いてAPIリクエストを送信する際は、タイムアウト(GASの標準では約6分、カスタム関数では30秒)を考慮し、応答待ち時間が長くなるような大量データの分析は避けるか、非同期処理(後述)を検討する必要があります。
エラー発生時のリトライ処理や、APIキーのセキュアな管理(PropertiesServiceの利用)など、Sourceで解説されている基本的なAPI連携の作法を遵守し、堅牢な通信基盤を構築しましょう。
分析結果の出力とレポートの自動生成
AIによって生成された分析コメントは、スプレッドシートの適切な場所に書き戻す必要があります。最もシンプルな方法は、データ行の隣に「AI分析」列を追加し、そこにテキストを格納することです。しかし、長文の分析レポートをセルに詰め込むと視認性が悪くなるため、別のシートに「分析レポート」という専用のダッシュボードを作成し、そこに整形して出力する方法も推奨されます。sheet.getRange().setValue() を使って書き込みますが、Markdown形式で出力されたテキストをスプレッドシート上で見やすく表示するために、セル内改行や書式設定をGASで制御する工夫も必要です。
さらに高度な実装として、SourceやSourceで触れられているように、分析結果をGoogleドキュメントのテンプレートに流し込み、PDF化して経営陣にメール送信するところまでを自動化するパイプラインを構築することも可能です。これにより、担当者はスプレッドシートを開いてボタンを押すだけで、会議資料の一次案が完成しているという状態を作り出せます。出力先をスプレッドシートに限定せず、SlackやChatworkへの通知(Source、)と組み合わせることで、異常値検知のアラートシステムとしても機能させることができます。
データの「保存場所」と「表示場所」を適切に設計し、ユーザーにとって最も価値のある形で情報を提供するUI/UXデザインの視点が求められます。
定期実行トリガーによるモニタリングの自動化
売上分析は、日次、週次、月次といった定期的なサイクルで行われる業務です。GASの「時間主導型トリガー」を利用して、このプロセスを完全自動化します。例えば、毎日深夜に前日の売上データを集計し、AIによる速報コメントを生成して、翌朝9時に担当者のSlackに通知するといった運用が可能です。SourceやSourceで解説されているように、トリガー設定は自動化の要ですが、実行時間の制限やエラー時の通知設定には注意が必要です。
特に月次処理のような重い処理を行う場合は、処理がタイムアウトしないように、データ取得、計算、AI分析、書き込みといった工程を分割して実行する、あるいは処理対象を絞り込むといったパフォーマンスチューニングが必要です。また、休日や祝日に不要な通知が飛ばないように、カレンダーAPIと連携して営業日判定を行うロジックを組み込むことも、実用的なシステムには欠かせません。自動化されたシステムは、人間が意識しなくてもバックグラウンドで価値を生み出し続ける「デジタルワーカー」として機能します。
エラーハンドリングとフィードバックループ
AIの出力は確率的であり、常に100%完璧な回答が返ってくるとは限りません。時には不適切な分析や、文脈にそぐわない提案が含まれることもあります。そのため、システムには人間による確認と修正(Human-in-the-loop)のプロセスを組み込むことが重要です。GASで出力した分析コメントを、担当者が修正できる運用にしておき、修正された内容をログとして蓄積します。
将来的には、この修正履歴をFew-Shotプロンプティングの事例(Shot)としてAIに再学習(コンテキスト注入)させることで、組織固有の分析観点やトーン&マナーをAIに学習させ、精度を向上させていくエコシステムを構築できます。また、APIエラーや予期せぬデータ形式に対する例外処理(try…catch)を徹底し、システムが停止した場合でも速やかに管理者に通知が届く仕組み(Source)を整備します。エラーを単なる失敗として処理するのではなく、システム改善のシグナルとして捉え、継続的なメンテナンスを行う姿勢が開発者には求められます。
セキュリティとデータガバナンス
売上データという極めて機密性の高い情報を扱う以上、セキュリティへの配慮は最優先事項です。Sourceでも指摘されているように、安易に外部のAIモデルにデータを送信することは情報漏洩のリスクを伴います。利用するAPI(Gemini APIやOpenAI API)のデータ利用ポリシーを確認し、送信データがモデルの学習に利用されない設定(オプトアウト)になっていることを確約する必要があります。また、顧客名や個人名が含まれる場合は、送信前にハッシュ化やマスキング処理を行い、匿名化された状態で分析させる実装が必須です。
社内のセキュリティガイドラインに準拠し、APIキーの管理を徹底する(ハードコーディングせず、スクリプトプロパティやGCPのSecret Managerを利用する)ことはもちろん、誰がいつスクリプトを実行し、どのようなデータが出力されたかを追跡できるログ管理の仕組みも導入すべきです。
Sourceにあるように、コード自体のバージョン管理(Git/claspの利用)を行い、意図しない変更や「野良GAS」化を防ぐガバナンス体制を構築することも、プロフェッショナルな開発者の責務です。
開発者としての進化:データ分析官からAI指揮官へ
本章で構築したシステムは、従来人間が行っていた「集計・分析・報告」という一連の業務プロセスをAIに代行させるものです。これにより、人間は「AIが提示した仮説を検証する」「最終的な意思決定を下す」「新たな戦略を構想する」という、より高次な業務に集中できるようになります。開発者としての役割も、単にコードを書くことから、AIという強力なリソースを指揮し、ビジネスの成果に直結するシステムをデザインする「アーキテクト」や「オーケストレーター」へと変化しています。
公式ドキュメント(Source)やGoogle Cloud Skills Boostなどの学習リソースを活用し、GASやAIモデルの最新仕様を常にキャッチアップすることはもちろん、コミュニティ(Source、)での知見共有を通じて、自身の技術力を高め続ける姿勢が重要です。AIに使われるのではなく、AIを使いこなし、組織の意思決定スピードを劇的に加速させる。そのような変革のリーダーとして、この自動分析システムを現場に実装し、磨き上げていってください。