非構造化データの資産化と定性分析の自動化アーキテクチャ
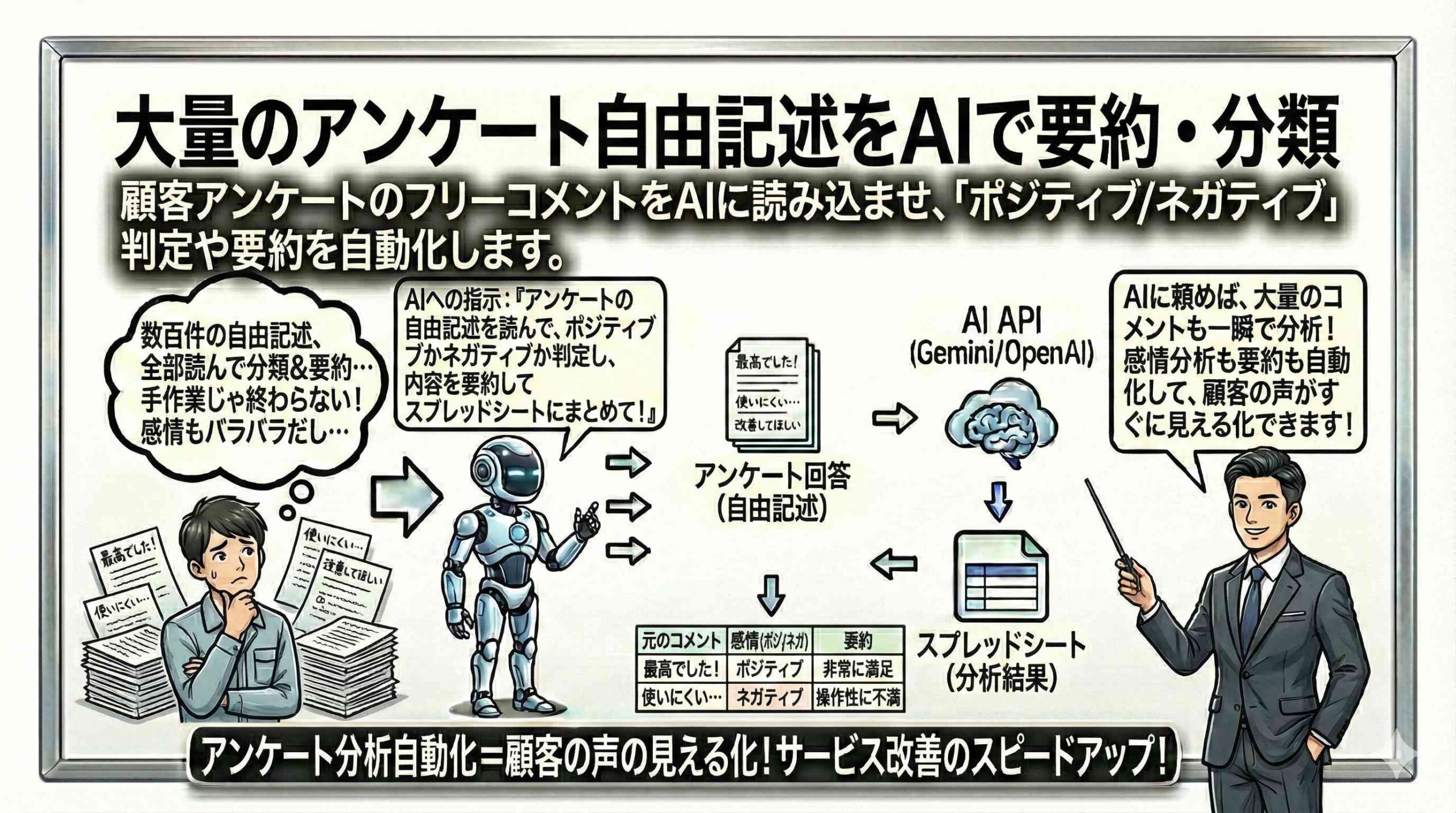
企業活動において、顧客の声(Voice of Customer:VoC)は改善と革新の源泉です。しかし、アンケートのフリーコメント欄や問い合わせフォームに寄せられるテキストデータは、その量の膨大さと非定型な性質から、定量データのように簡単に集計・分析することが困難でした。従来、これらのデータを活用するためには、担当者が一件ずつ目視で読み込み、手作業で「ポジティブ・ネガティブ」のラベル付けを行ったり、内容を要約してレポートにまとめたりする必要がありました。このプロセスは極めて労働集約的であり、担当者の主観によるバイアスが入り込む余地があるだけでなく、リアルタイムでの意思決定を阻害する要因となっていました。Google Apps Script(GAS)と生成AIのAPIを統合することで、このボトルネックを解消し、数千、数万件に及ぶテキストデータを自動的かつ客観的に構造化データへと変換するパイプラインを構築することが可能になります,。
本章では、スプレッドシートに蓄積された大量のアンケート回答を対象に、AIを用いて感情分析(Sentiment Analysis)と要約(Summarization)を一括で行うバッチ処理システムの設計と実装について詳述します。単にAPIを呼び出すだけでなく、業務要件に耐えうる分類基準の策定、大量データを処理する際のGASの実行時間制限(6分の壁)を回避するための設計パターン、そして出力結果を後続のBIツール(Looker Studioなど)で活用しやすい形式に整形するデータエンジニアリングの観点まで、プロフェッショナルな開発者が必要とする知識を網羅的に解説します。非構造化データを構造化し、経営判断に直結するインサイトを導き出すための技術基盤を構築しましょう。
分析タクソノミーの設計とプロンプトエンジニアリングによる定義
AIによる自動分類を成功させる鍵は、コードを書く前の「設計」にあります。人間が感覚的に行っていた「これは苦情だ」「これは要望だ」という判断基準を、明確な言語化されたルール(タクソノミー)として定義し、それをプロンプトに落とし込む作業が不可欠です。例えば、単に「ポジティブかネガティブか判定せよ」という指示だけでは、AIの判定は揺らぎやすく、分析の精度が安定しません。「製品の機能に関する不満はネガティブ、価格に対する納得感はポジティブ、機能追加の要望はニュートラル」といったように、具体的な評価軸と判定ロジックをプロンプト内で定義する必要があります。
また、出力形式の制御も極めて重要です。APIからのレスポンスをスプレッドシートに書き込む際、自由記述の文章で返されてしまうと、後処理が煩雑になります。そこで、プロンプト内で「出力は必ずJSON形式とし、以下のスキーマに従うこと:{“sentiment”: “Positive”, “category”: “UI/UX”, “summary”: “ボタンの配置が分かりにくいという指摘”}」のように、データ構造を厳密に指定します。これにより、GAS側でのパース処理(JSON.parse)が容易になり、エラーの発生率を劇的に低下させることができます。
Few-Shotプロンプティングを活用し、入力と理想的な出力のペアを数件例示することで、AIに対して期待する分類の粒度や要約の長さを学習させるテクニックも有効です。開発者は、AIを単なる魔法の箱として扱うのではなく、ロジックに基づいて制御可能な「確率的関数」として設計する視点を持つ必要があります。
UrlFetchAppによるバッチ処理の実装とペイロードの最適化
大量のデータを処理する場合、一件ずつAPIリクエストを送信する実装は非効率であり、GASの実行時間制限やAPIのレートリミット(一定時間あたりのリクエスト数制限)に抵触するリスクが高まります。プロフェッショナルな実装では、スプレッドシートからデータを二次元配列として取得(getValues)した後、適切なバッチサイズ(例えば10件〜50件程度)に分割して処理を行うか、あるいは一件ごとの処理であっても、リクエスト間隔を調整するロジックを組み込みます。APIへのリクエストペイロードを構築する際は、それぞれの行のコンテキスト(回答者の属性や購入履歴など)も合わせてAIに渡すことで、より精度の高い分析が可能になります。例えば、「30代男性」という属性情報を加味することで、同じ「普通」というコメントでも、その背景にある意図をより深く解釈できる可能性があります。
APIリクエストの実装には UrlFetchApp.fetch メソッドを使用しますが、ここでは contentType: 'application/json' ヘッダーの設定と、ペイロードのJSONシリアライズ(JSON.stringify)を正確に行う必要があります。また、APIによっては、複数のテキストを一度のリクエストでまとめて送信し、一括で分析結果を受け取る「バッチAPI」機能を提供している場合もあります。
利用するAIモデルの仕様(Google Gemini APIやOpenAI APIなど)を確認し、トークン単価やスループットを考慮して、最もコストパフォーマンスの高いリクエスト方法を選択することが、エンジニアとしての重要な責務です。通信エラーやタイムアウトが発生した場合に備え、 muteHttpExceptions: true オプションを設定し、レスポンスコードに応じた適切な例外処理を実装することも忘れてはなりません。
JSONレスポンスのパースとデータバリデーション
AIから返却されたJSON形式のレスポンスを、GASで扱えるJavaScriptオブジェクトに変換し、スプレッドシートの各列に展開するプロセスについて解説します。 JSON.parse(response.getContentText()) を用いて解析を行いますが、生成AIは稀にJSONの構文エラーを含むテキスト(余計な説明文やMarkdownの記号など)を返すことがあります。これに対処するため、正規表現を用いてJSON部分のみを抽出するクリーニング処理や、 try...catch 構文を用いたパースエラー時のリカバリー処理を実装します。
さらに、パースされたデータが期待するスキーマ(構造)を持っているかを検証(バリデーション)することも重要です。例えば、「sentiment」フィールドが存在するか、その値が事前に定義した「Positive/Negative/Neutral」のいずれかであるかを確認します。もし未知の値が含まれていた場合は、「要確認」というフラグを立ててログに残し、人間が後から確認できるようにするフェイルセーフな設計が求められます。このように、AIの出力を鵜呑みにせず、システム側で品質を担保するガードレールを設けることが、信頼性の高い自動化システムを構築するための要諦です。
検証済みのデータは、再び二次元配列に整形し、 range.setValues() メソッドを用いてスプレッドシートに一括で書き込みます。この際、既存のデータを上書きしないよう、書き込み範囲の指定には細心の注意を払います。
実行時間制限(6分の壁)の克服とレジューム機能の実装
GASのスクリプト実行には「6分間」という厳格な時間制限があります。数千件のアンケートデータをAIで分析する場合、APIのレスポンス待ち時間を含めると、全件処理するのに6分以上かかることが一般的です。この制限を回避し、処理を完遂させるためには、「レジューム(途中再開)機能」の実装が不可欠です。具体的には、スクリプトプロパティ(PropertiesService)を利用して、「現在何行目まで処理が完了したか」という状態を記録し続けます。
スクリプトの冒頭で PropertiesService.getScriptProperties().getProperty('PROCESSED_ROW') を呼び出し、処理開始行を取得します。ループ処理の中で、現在時刻と開始時刻を比較し、経過時間が5分を超えた段階で処理を中断します。その際、現在の行番号をスクリプトプロパティに保存し、 ScriptApp.newTrigger メソッドを用いて自身の関数を1分後に再度実行するトリガーを動的に作成してから終了します。次回の実行時には、保存された行番号から処理が再開されるため、理論上は無限のデータを処理し続けることが可能になります。この「分割実行パターン」は、GASを用いた大規模データ処理における標準的なアーキテクチャであり、プロフェッショナルな開発者であれば必ず習得しておくべき技術です。
処理が全件完了した際には、トリガーとプロパティを削除し、管理者に完了通知メールを送信するクリーンアップ処理も忘れずに実装しましょう。
エラーハンドリングとリトライ戦略による堅牢性の確保
外部API連携において、ネットワークの一時的な不調や、API側のレート制限(Rate Limit/429エラー)による失敗は避けられません。特にバッチ処理中にエラーが発生して停止してしまうと、どこまで処理できたかが不明確になり、データの不整合や重複処理の原因となります。これを防ぐために、指数バックオフ(Exponential Backoff)アルゴリズムを用いたリトライロジックを実装します。APIリクエストが失敗した場合、即座にエラーとするのではなく、1秒、2秒、4秒と待機時間を倍増させながら数回再試行を行います。
それでも成功しない場合は、その行を「エラー」として記録し、次の行の処理へと進む(スキップする)設計にします。スプレッドシートに「ステータス」列を設け、処理済み、処理中、エラーといった状態を可視化することで、運用担当者が状況を把握しやすくなります。また、重大なエラー(APIキーの無効化や認証エラーなど)が発生した場合は、即座に処理を中断し、SlackやChatworkなどのチャットツールにアラートを通知する仕組みを組み込みます。エラーを握りつぶさず、適切に記録・通知し、リカバリー可能な状態を維持することが、業務システムの安定稼働を支える基盤となります。 console.log や console.error を活用して詳細な実行ログをGoogle Cloudのログエクスプローラに残すことも、トラブルシューティングの迅速化に寄与します。
コスト管理とキャッシュ戦略によるAPI利用の最適化
従量課金のAI APIを利用する場合、コスト管理は重要な課題です。無駄なAPI呼び出しを削減するために、キャッシュ戦略を検討します。過去に処理したアンケート回答と同じ内容が再度入力された場合、再度APIを呼び出すのではなく、過去の分析結果を再利用することでコストと時間を節約できます。具体的には、回答テキストのハッシュ値(MD5など)を生成し、それをキーとして分析結果を別のシートやCacheServiceに保存しておく方法があります。
また、開発段階やテスト運用においては、安価なモデル(Gemini 1.5 FlashやGPT-4o miniなど)を使用し、本番運用でより高精度なモデルに切り替えるといったモデル選定の戦略も有効です。さらに、APIの利用状況(トークン数やリクエスト回数)をスプレッドシート上で集計し、日次のコストをモニタリングするダッシュボードを作成することで、予算超過のリスクを未然に防ぐことができます。企業のIT予算を預かる開発者として、技術的な実現だけでなく、経済合理性に基づいたシステム設計を行う視点が求められます。
個人情報保護とセキュリティガバナンスの徹底
アンケートの自由記述欄には、稀に顧客の氏名や電話番号、メールアドレスといった個人情報(PII)が含まれている場合があります。これらの情報をそのまま外部のAI APIに送信することは、プライバシー保護の観点や企業のセキュリティポリシー上、大きなリスクとなります。したがって、APIにデータを送信する前に、正規表現を用いてメールアドレスや電話番号のパターンを検出し、それらを [EMAIL] [PHONE] といったプレースホルダーに置換するマスキング処理をGAS側で実装することを強く推奨します。
また、利用するAIサービスの利用規約を確認し、API経由で送信されたデータがAIの学習(トレーニング)に利用されない設定(オプトアウト)になっていることを確実に担保する必要があります。Google Workspaceのエンタープライズ契約下のGeminiや、OpenAIのAPI利用においては、通常デフォルトで学習に利用されない設定になっていますが、念のため公式ドキュメントで最新の仕様を確認し、ステークホルダーに説明できる状態にしておくことが重要です。
APIキーの管理についても、スクリプト内にハードコーディングせず、スクリプトプロパティやGCPのSecret Managerを利用して厳重に管理し、アクセス権限を持つユーザーを最小限に絞るなど、徹底したセキュリティ対策を講じましょう。
分析結果の可視化とビジネスアクションへの接続
AIによる分析と分類が完了したデータは、スプレッドシート上でピボットテーブルやグラフを用いて可視化します。「製品カテゴリごとのネガティブ意見の割合推移」や「頻出する要望キーワードのランキング」などをダッシュボード化することで、現場の担当者や経営層が直感的に状況を把握できるようになります。さらに、ネガティブな判定が出た回答については、即座に担当者にSlackで通知を飛ばしたり、カスタマーサポートシステム(ZendeskやSalesforceなど)にチケットを起票したりするといった、次のアクションを自動トリガーする仕組みへと発展させることも可能です。
データは分析して終わりではなく、具体的な改善活動に繋がって初めて価値を生みます。GASとAIを活用することで、データの収集から分析、そしてアクションまでのリードタイムを極限まで短縮し、顧客の声に即応できる組織体制を構築することが、本システムの最終的なゴールです。このように、技術とビジネスの架け橋となり、データドリブンな意思決定を支援するシステムを構築することこそが、DX時代における開発者の真価と言えるでしょう。
開発者としての継続的な学習とコミュニティへの貢献
本章で取り上げた技術要素は、GAS、API連携、非同期処理、データエンジニアリングと多岐にわたります。これらの技術は日々進化しており、AIモデルの性能向上やGASの仕様変更に追随していくためには、継続的な学習が欠かせません。Google公式のドキュメント(Reference)やリリースノートを定期的にチェックし、Google Cloud Skills Boostなどの学習プラットフォームを活用して、体系的な知識をアップデートし続ける姿勢が重要です。
また、自身が構築したシステムの知見や、遭遇したエラーとその解決策を、QiitaやZenn、技術ブログなどでコミュニティに共有することは、自身の理解を深めるだけでなく、業界全体の技術レベル向上に貢献する素晴らしい活動です。コードの断片やプロンプトの例を共有するだけでも、多くの開発者の助けとなります。「AIに使われる」のではなく、AIという強力なテクノロジーを指揮し、組織の課題解決に活用できる「AIオーケストレーター」としてのスキルを磨き続け、より高度なDXを実現していってください。あなたの書くコードが、組織の未来を変える一歩となります。