DOMツリーの構造とノードの概念:Webページの家系図
Webページは「木」でできている
私たちが普段見ているWebページは、一見すると平面的な文書に見えますが、ブラウザの内部では「DOM(Document Object Model)」と呼ばれる階層構造のデータとして管理されています。HTMLを書くとき、<html>タグの中に<body>タグがあり、その中に<div>や<ul>があり、さらにその中に<li>がある……というように、タグが入れ子になっていることを思い出してください。この入れ子構造を図式化すると、根(ルート)から幹が伸び、枝が分かれ、葉がつく「木(ツリー)」のような形になります。これを「DOMツリー」と呼びます。
JavaScriptを使ってWebページを操作するということは、すなわちこのDOMツリーの特定の場所にアクセスし、内容を書き換えたり、枝を付け替えたりすることを意味します。ReactやVue.jsといった最新のフレームワークを使っている場合でも、裏側で動いている仕組みはこのDOM操作そのものです。したがって、DOMの構造を正しく理解することは、どんな技術トレンドになっても通用するエンジニアとしての基礎体力となります。
「要素」と「ノード」の違い
DOMツリーを構成する一つ一つの部品を「ノード(Node)」と呼びます。初心者の方が混同しやすいのが「要素(Element)」と「ノード」の違いです。
• 要素ノード(Element Node): <div>, <p>, button などのHTMLタグそのものを指します。私たちが主に操作したいのはこれです。
• テキストノード(Text Node): タグの中に書かれた文字(テキスト)です。
• 属性ノード(Attribute Node): id="main" や class="active" といった属性情報です。
例えば、<div>こんにちは</div> というHTMLがあった場合、<div>という要素ノードの中に、「こんにちは」というテキストノードが含まれているという親子関係になります。 JavaScriptで親要素や兄弟要素を取得する際、メソッドによっては「テキストノード」や「改行(空白のテキストノード)」まで取得してしまうものがあります。自分が今、HTMLのタグ(要素)を扱いたいのか、それともノード全体を扱いたいのかを意識することが、DOM操作のトラブルを防ぐ第一歩です。
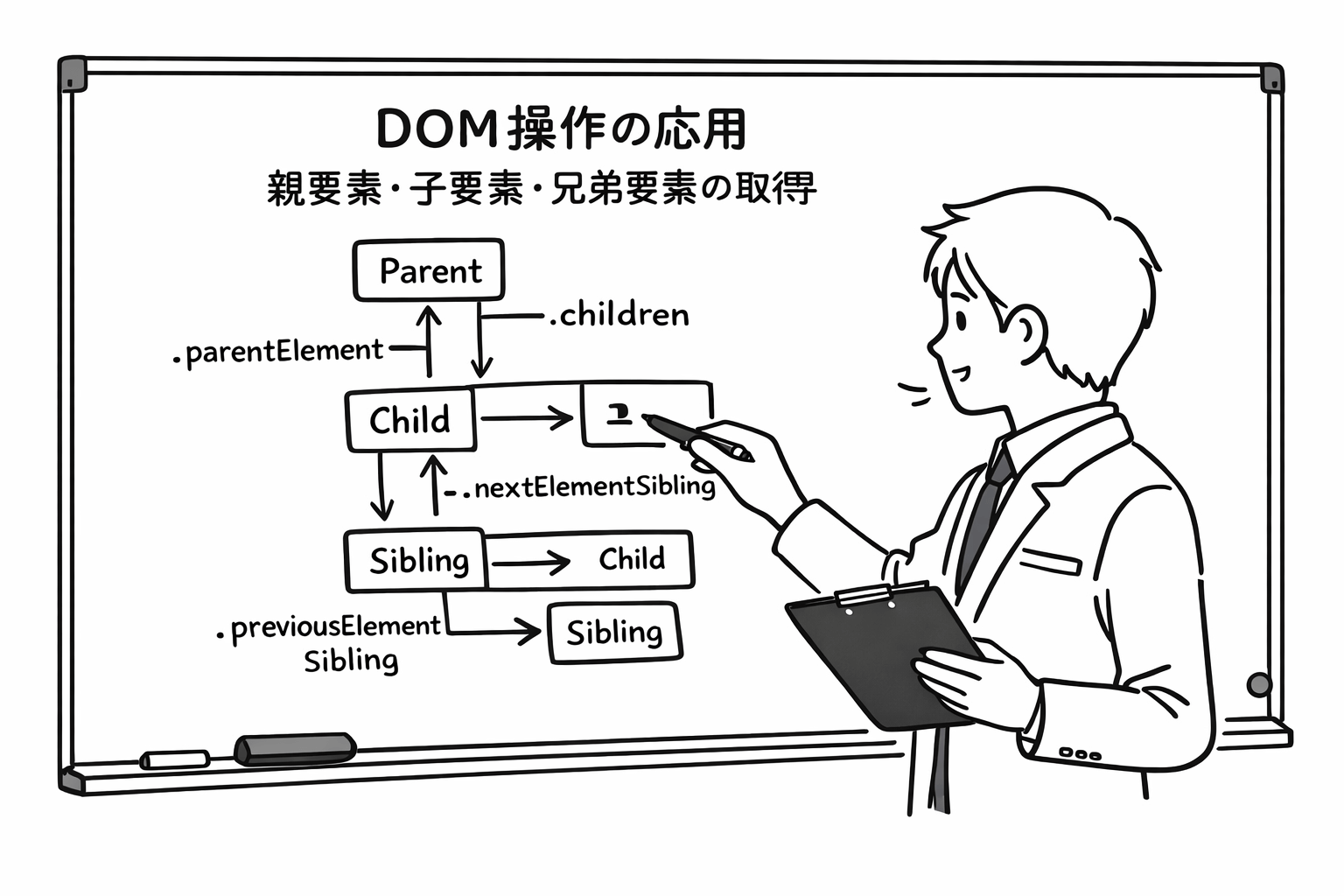
親要素の取得:parentNodeによる階層の遡上
親へのアクセスが必要なシーン
DOM操作において「親要素」を取得したい場面は非常に多く存在します。典型的な例は「削除ボタン」の実装です。 例えば、ToDoリストアプリを想像してください。リスト項目(<li>)の中に「削除」ボタンが含まれています。ユーザーがこのボタンをクリックしたとき、消すべきなのは「ボタン自身」ではなく、ボタンを含んでいる「リスト項目全体(親要素)」です。 このように、イベントが発生した要素(子)を起点として、そのコンテナとなる要素(親)を操作したい場合に、親要素の取得が必要になります。
parentNodeプロパティの使い方
ある要素の直上の親要素を取得するには、parentNodeプロパティを使用します。
const child = document.querySelector('.child-element');
const parent = child.parentNode;
このコードでは、.child-elementというクラスを持つ要素を取得し、その親要素をparentという変数に格納しています。もし親要素が存在しない場合(例えば<html>要素の親など)、nullが返されます。
親要素を辿る際の注意点
parentNodeは、一つ上の親しか取得できません。もし、「3つ上の親要素を取得したい」という場合は、element.parentNode.parentNode.parentNodeのようにプロパティを連鎖させる必要があります。しかし、この方法はHTMLの構造が変わると動かなくなるため、非常に脆いコードになってしまいます。 より柔軟に、特定の条件に合致する最も近い祖先要素を探したい場合は、closest()メソッド(モダンブラウザで利用可能)を併用することが推奨されますが、基本となるのはこのparentNodeによる直近の親の取得です。DOMツリーを「下から上へ」登っていく操作は、イベント処理(特にイベントのバブリングを利用した委譲)とセットで使われることが多いため、確実にマスターしておきましょう。
子要素の取得:childrenとchildNodesの決定的な違い
要素を取得する2つのアプローチ
親要素から見て、その直下にある要素を「子要素」と呼びます。例えば<ul>タグにとっての<li>タグがこれに当たります。JavaScriptで子要素を取得する方法には、主にchildNodesプロパティとchildrenプロパティの2種類がありますが、この2つは似て非なるものです。ここを理解していないと、予期せぬバグに悩まされることになります。
childNodes:すべてのノードを取得する
childNodesプロパティは、その要素に含まれる「すべてのノード」を返します。ここにはHTML要素だけでなく、テキストノード(文字)も含まれます。
const list = document.querySelector('ul');
const allNodes = list.childNodes;
注意が必要なのは、HTMLコード上の「改行」や「インデント(空白)」もテキストノードとして扱われる点です。
<ul>
<li>Item 1</li>
<li>Item 2</li>
</ul>
このようなHTMLの場合、<li>と<li>の間の改行コードも一つのノードとしてカウントされるため、childNodesの結果には、<li>要素だけでなく空白のテキストノードが含まれてしまいます。そのため、「1番目の項目を取得したい」と思ってインデックス0にアクセスしたら、実は改行コードだった、ということが頻繁に起こります。
children:HTML要素のみを取得する
一方、childrenプロパティは、子ノードの中から「HTML要素(要素ノード)」だけをフィルタリングして返してくれます。
const listItems = list.children;
この場合、改行やテキストは無視され、純粋に<li>タグだけがリストとして取得されます。Web開発において、スタイルの変更やクラスの付け替えを行いたい対象はほとんどの場合HTML要素です。したがって、実務ではchildNodesよりも、このchildrenプロパティを使用するケースが圧倒的に多いでしょう。 「中身のテキストも含めて厳密に操作したいならchildNodes」「HTMLタグだけを扱いたいならchildren」と使い分けるのがポイントです。
兄弟要素の取得:nextElementSiblingによる横移動
隣の要素へのアクセス
DOMツリーにおいて、同じ親を持ち、隣り合っている要素同士を「兄弟要素(Sibling)」と呼びます。リストの項目同士や、見出し(h2)とその直後の段落(p)などがこれに該当します。 「次の項目にフォーカスを移動する」「アコーディオンメニューで、クリックされた見出しの『次にある』コンテンツを開く」といったUIを実装する際に、兄弟要素の取得が必要になります。
nextSiblingとnextElementSibling
親要素や子要素の時と同様に、兄弟要素の取得にも「ノード」を扱うものと「要素」を扱うものの2種類が存在します。
1. nextSibling: すぐ次にある「ノード」を取得します。ここでもやはり、HTMLの改行や空白が「テキストノード」として挟まっている場合、それが取得されてしまいます。
2. nextElementSibling: テキストノードをスキップして、すぐ次にある「HTML要素」を取得します。
3. 直感的に「次のタグ」を取得したい場合は、間違いなくnextElementSiblingを使うべきです。
同様に、一つ「前」の兄弟要素を取得するためのプロパティとして、previousSibling(前のノード)とpreviousElementSibling(前の要素)も用意されています。これらを組み合わせることで、親を経由せずに横方向へのDOMトラバーサルが可能になります。
querySelectorによる相対的な要素検索
document以外からの検索
これまでquerySelectorやquerySelectorAllを使う際、常にdocument.querySelector(...)のように、文書全体(document)を起点にして検索していたかもしれません。しかし、これらのメソッドは、特定の「要素」に対して実行することも可能です。これを活用すると、検索範囲をその要素の内側だけに限定することができます。
スコープを限定した検索のメリット
例えば、画面上に「商品カード(.product-card)」が複数並んでいるとします。それぞれのカードには「タイトル(.title)」や「価格(.price)」が含まれています。 ここで、ある特定のカードの中にあるタイトルだけを取得したい場合を考えます。
const card = document.querySelector('#target-card'); // 特定の親要素を取得
const title = card.querySelector('.title'); // その親の中にある.titleだけを探す
このように書くことで、他のカードに含まれる.titleに影響されることなく、目的の要素だけを確実に取得できます。 これは、childrenプロパティでは対応しきれない、「子要素のさらに孫要素」や「特定のクラスを持つ子孫要素」をピンポイントで探したい場合に非常に強力なテクニックです。DOMツリー全体を毎回探索するよりもパフォーマンスが良く、コードの意図(どのコンテキストの中の要素なのか)も明確になります。
NodeListとHTMLCollection:リスト操作の落とし穴
配列のように見えて配列ではない
querySelectorAllの返り値であるNodeListや、childrenプロパティの返り値であるHTMLCollectionは、一見するとJavaScriptの配列(Array)のように見えます。
const listItems = document.querySelectorAll('li');
console.log(listItems); // インデックスでアクセスできる
console.log(listItems.length); // lengthプロパティがある
しかし、これらは「配列風オブジェクト(Array-like Object)」であり、本物の配列ではありません。そのため、配列特有の便利なメソッド(map, filter, reduceなど)を直接使うことができない場合があります。
NodeListとHTMLCollectionの違い
• NodeList: querySelectorAllなどで返されます。最近のブラウザではforEachメソッドを持っていますが、古いブラウザ(IEなど)では持っていませんでした。静的なリスト(取得時点の状態を保持)であることが多いです。
• HTMLCollection: childrenやgetElementsByClassNameで返されます。こちらはforEachを持っていません。また、「生きた(Live)」コレクションであり、DOMの状態が変化すると自動的に中身も更新されるという特徴があります。
この違いを理解していないと、「forEachが動かない!」「要素を削除したのにリストの数が変わらない(あるいは勝手に変わる)」といった不可解な現象に遭遇することになります。
ループ処理による複数要素の一括操作
配列への変換テクニック
前述の通り、HTMLCollectionなどはそのままでは扱いにくい場合があります。そこで、これらをJavaScriptの標準的な配列(Array)に変換してしまうのが、モダンな開発における定石です。 最も簡単な方法は、ES6から導入された「スプレッド構文(…)」を使うことです。
const htmlCollection = document.querySelector('ul').children;
const array = [...htmlCollection]; // 配列に変換!
一度配列に変換してしまえば、forEachはもちろん、mapやfilterなど、JavaScriptの強力な配列メソッドを自由自在に使えるようになります。
forEachによる繰り返し処理
複数の要素に対して同じ処理(例えば、すべてのボタンにクリックイベントを設定するなど)を行いたい場合、ループ処理は必須です。
const buttons = document.querySelectorAll('.btn');
buttons.forEach((button) => {
button.addEventListener('click', () => {
console.log('クリックされました');
});
});
NodeListはモダンブラウザであれば直接forEachが使えますが、互換性を気にする場合やHTMLCollectionを扱う場合は、前述の配列変換を行うか、Array.from()メソッドを使用するのが安全で確実な方法です。
クラスと属性の操作:DOMの状態を変更する
classListによるスタイルの切り替え
親や兄弟要素を取得した後、その要素に対して何らかの変化を与えたい場合、最も一般的なのが「クラスの付け替え」です。 element.classNameでクラス文字列全体を上書きすることもできますが、classListプロパティを使うのが断然おすすめです。
• element.classList.add('active'): クラスを追加
• element.classList.remove('active'): クラスを削除
• element.classList.toggle('active'): クラスがあれば削除、なければ追加
• element.classList.contains('active'): クラスを持っているか判定(true/false)
例えば、「メニューボタン(兄弟要素)をクリックしたら、メニュー本体(自分)に.is-openクラスをつけて表示する」といったUI操作は、このclassListを使って実装します。
カスタムデータ属性(data-*)の活用
JavaScriptからDOMに独自のデータを持たせたい場合、HTML5の標準仕様である「カスタムデータ属性」が役立ちます。属性名をdata-で始めることで、自由に値を設定できます。
<div id="user" data-user-id="123" data-role="admin">...</div>
JavaScriptからはdatasetプロパティを使ってアクセスします。
const user = document.querySelector('#user');
console.log(user.dataset.userId); // "123"(キャメルケースに自動変換される)
これを活用すれば、DOMの階層関係だけでなく、要素自体に埋め込まれたIDや状態に基づいて、より高度なロジックを組むことができます。
要素の生成・挿入・移動:DOMツリーの書き換え
insertAdjacentElementによる挿入
取得した親要素に対して、新しい子要素を追加したい場合はcreateElementで要素を作り、appendChildなどで挿入します。しかし、もっと柔軟に「親要素の直前」や「子要素の先頭」など、位置を細かく指定したい場合はinsertAdjacentElementメソッドが便利です。
• 'beforebegin': 対象要素の直前(兄弟として挿入)
• 'afterbegin': 対象要素の内部の最初(最初の子として挿入)
• 'beforeend': 対象要素の内部の最後(最後の子として挿入。appendChildと同じ)
• 'afterend': 対象要素の直後(兄弟として挿入)
const parent = document.querySelector('#parent');
const newElement = document.createElement('div');
parent.insertAdjacentElement('afterbegin', newElement);
これにより、既存のDOMツリーの関係性を壊すことなく、狙った位置に正確に要素を配置できます。
要素の移動と削除
既存の要素に対してappendChildやinsertAdjacentElementを行うと、その要素は複製されるのではなく「移動」します。DOMノードはツリー上の1箇所にしか存在できないためです。これを利用して、リストの並び替え機能などを実装できます。 また、要素を削除したい場合は、対象の要素に対してremove()メソッドを呼び出すだけで、DOMツリーから切り離すことができます。
まとめ:DOMトラバーサルで実現するインタラクティブなWeb
相対的な操作の重要性
ここまで、親(parentNode)、子(children)、兄弟(nextElementSibling)の取得方法を見てきました。これらがなぜ重要かというと、Webアプリケーションでは「どの要素が操作されるか」が事前に決まっていないことが多いからです。 ユーザーが「たくさんあるリストの中のどれか」をクリックしたとき、プログラムは「クリックされたその要素」を起点(event.target)として、相対的に親を探したり、隣の要素を書き換えたりする必要があります。IDですべてを指定する静的な操作ではなく、この「関係性に基づいた動的な操作」こそが、JavaScriptによるDOM操作の真骨頂です。
フレームワークの裏側にある基礎
現在ではReactやVue.jsなどのフレームワークがDOM操作を自動化してくれるため、直接これらのメソッドを書く機会は減っているかもしれません。しかし、フレームワークが裏側で行っているのは、まさに今回解説したDOMトラバーサルと操作そのものです。 「なぜかスタイルが崩れる」「イベントが発火しない」といったトラブルに直面したとき、DOMのツリー構造と親子兄弟の関係性を正しくイメージできれば、解決への道筋はすぐに見つかります。基本となるDOM操作をマスターして、自在にWebページを操れるエンジニアを目指しましょう。